
[머신러닝]KNN(K-Nearest Neighbor) 최근접 이웃알고리즘으로 오렌지와 자몽 구별하기
사이킷런(scikit-learn)을 사용하여 KNN(K-Nearest Neighbor, 최근접 이웃 알고리즘)예제를 진행해보았다.
개발환경은 구글 colab에서 진행하였다.
오렌지와 자몽의 지름과 무게 데이터를 가지고, 훈련과 테스트 데이터를 나누어 학습하고, 이를 바탕으로 정답이 없는 예시를 넣었을때 이를 분류 가능하도록 해보자.

사이킷런(scikit-learn)이란?

사이킷런은 머신러닝 오픈소스 라이브러리이다.
기본적인 데이터 세트(붓꽃,보스턴집값, 당뇨병관련 등등)도 제공하고, 머신러닝 API(의사결정트리, 최근접이웃알고리즘, 회귀분석 등등)도 포함 되어 있다. 먼저 만들어져 있는 라이브러리를 활용하여 머신러닝 스터디를 진행하고자 한다. 추후 따로 사이킷런에 대한 좀 더 자세한 포스팅을 진행하겠다.
KNN(K-Nearest Neighbor), 최근접 이웃 알고리즘이란?
라벨(정답)이 있는 데이터 속에서 클래스를 나누고, 라벨(정답)이 없는 데이터를 정답이 있는 데이터와 유사한 클래스로 분류(분류로 사용하기도, 회귀일때 사용하기도 하지만 일단 여기서는 분류로 진행했다. )하기 위한 알고리즘이다. 가장 고전적이고 직관적이라는 특징을 가진다. 여기서 이야기하는 고전적(classic)이라는 것은 단순히 오래되었다는 뜻은 아니고, 시대가 지나도 계속 활용 된다는 뜻으로 말한다.
KNN은 게으른 학습자(Lazy learner)기도 하다. 게으르다는 표현은 느리거나 그런게 아닌 알고리즘이 판별함수를 학습(추상화)하는게 아니라 데이터셋을 저장하여 분류하기 때문이다.(비모수 학습, Non-parametric)
KNN의 기본적인 알고리즘
- 분류하려는 샘플을 기준으로 일정한 거리(유클리드 거리 Euclidean distance)의 k개의 최근접 이웃을 고르고, 거기서 과반수의 투표를 통해 분류된다.





위 슬라이드를 통해 알 수 있는 점
1. k의 갯수가 짝수일 때 동점이라는 문제가 생길 수 있다. : 과반수 투표 동일시 사이킷런 knn은 거리가 가까운, 거리가 같다면 훈련데이터셋에서 먼저 나온 샘플로 판별한다. 다만 k의 값을 무조건 홀수로 정해야 하는 것은 아니다!! 입력값과, 분류할 종류에 따라 적절하게 설정 해야 한다.(3개 그룹으로 분류시 k=3이면 모든 그룹에 해당되서 결론 못내릴 수도 있음.)
2. k 측정 거리가 너무 커지면 데이터 주변의 지역분포에 민감하다. (5번 슬라이드, k=4일 때 오른쪽 아래 툭 튀어나온 주황색까지 포함) : 적당한 거리를 선택해야 한다.
3. 항목들이 많은(빈번한) 데이터가 예측을 지배하기도 하다. : 데이터가 많을 수록 최근접이웃이 되기 쉽기 때문이다. 이를 해결하기위해 k개의 최근접 이웃의 거리에 따른 가중치를 주는 방법이 있다.
KNN의 장점은?
단순, 성능좋음(효율적이다.), 훈련 단계가 빠르다.(분류하고 새로운 훈련데이터에 바로 적용가 능.)
KNN의 단점은?
모델 생성이 없어서 특징과 클래스간 관계 이해가 제한적이다. k거리와 갯수를 정해야 한다. 데이터 정규화를 진행해야한다. 데이터세트의 특징이 많으면 분류가 느려진다.
DATA 수집
kaggle에서 데이터셋을 csv형태로 다운로드 받았다.
www.kaggle.com/joshmcadams/oranges-vs-grapefruit
Oranges vs. Grapefruit
Orange and grapefruit diameter, weight, and color data.
www.kaggle.com
이를 가공하여 다음과 같이 colab에서 코드셀에 입력한다.
가공 데이터가 많아서 github 링크를 올립니다. 아래 github에서 데이터 셋을 복사하여 코드셀에 붙여 넣으세요.
github.com/dol42/knn_fruit/blob/main/dataset
dol42/knn_fruit
Contribute to dol42/knn_fruit development by creating an account on GitHub.
github.com
입력한 데이터로 그래프를 그려보았다.
#그래프를 그리기 위한 matplotlib라이브러리의 pyplot을 불러오고 그걸 plt라고 줄여 부르겠다.
import matplotlib.pyplot as plt
#오렌지의 데이터(지름과 무게)로 산점도 그래프를 그리겠다.
plt.scatter(orange_diameter,orange_weight)
#자몽의 데이터(지름과 무게)로 산점도 그래프를 그리겠다.
plt.scatter(grapefruit_diameter,grapefruit_weight)
#x축의 레이블은 지름'diameter'
plt.xlabel('diameter')
#y의 레이블은 무게'weight
plt.ylabel('weight')
#표의 타이틀은 "orange_grapefruit"
plt.title("orange_grapefruit")
#그래프를 출력
plt.show()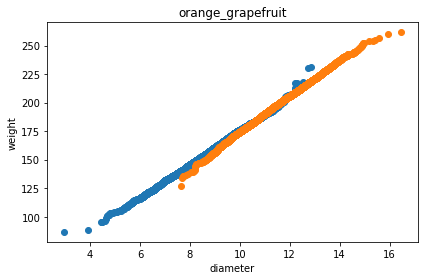
사이킷런 라이브러리를 이용하기 위해 데이터를 2차원으로 만들어주어야 한다. 이를 위해 다음과 같이 먼저 오렌지와 자몽의 데이터를 하나로 합쳐 주었다. (리스트형 데이터를 합침.)
#오렌지와 자몽의 리스트 데이터를 합쳐 하나로 만들어 준다.
diameter = orange_diameter + grapefruit_diameter
weight = orange_weight + grapefruit_weight합쳐진 데이터를 for문과 zip함수를 사용하여 각각 지름(diameter)과 무게(weight) 요소로 2차원 배열로 만들어 준다.
#fruit_data라는 함수에 d,w(각각 diameter과 weight의 약자)변수를 for문으로 반복, 각각 zip함수로 하나의 요소씩 넣는다.
fruit_data = [[d,w] for d,w in zip(diameter, weight)]
#잘 들어갔는지 확인해본다.
print(fruit_data)
정답 데이터를 더미 변수로 만들어준다.
#레이블(정답데이터)을 더미변수로 만들어준다.
#0(오렌지)을 5000개(갯수만큼) + 1(자몽)을 5000개(갯수만큼)
fruit_target = [0]*5000 +[1]*5000
#잘만들어졌는지 출력해보자.
print(fruit_target)
만든 데이터와 라벨의 갯수를 확인한다. 만약 갯수가 다르다면 매칭시킬 수 없기 때문에 다시 확인해 봐야한다.
#만든 데이터의 갯수와 정답데이터의 갯수를 각각 확인해보자.
print(len(fruit_data))
print(len(fruit_target))
가공한 데이터를 훈련데이터와 테스트데이터로 나누어 준다. 나는 80%는 훈련데이터로, 20% 테스트데이터(훈련된 모델이 잘 동작하는지 확인)로 나누어 주었다. 만약 이렇게 나누어 주지 않는다면 새로운 데이터를 넣어 주어야 한다.
from sklearn.model_selection import train_test_split
# x_train :
# x_test :
# y_train :
# y_test :
#train_test_split(데이터, 라벨데이터, shuffle: 섞을지 여부, test_size: 몇퍼센트로 나눌지, random_state= 랜덤시드, 이게 없으면 돌릴때마다 덤하게 나옴 )
x_train, x_test, y_train, y_test = train_test_split(fruit_data, fruit_target, shuffle=True, test_size=0.2, random_state=20)이렇게 훈련데이터와 테스트 데이터로 나누는 이유는 과적합(Overfitting)이 일어나지 않도록 하기 위함이다.
잘 나누어 졌는지 확인해보자.
print(len(x_train))
print(len(x_test))
print(len(y_train))
print(len(y_test))
Overfitting(과적합)
과적합은 머신러닝에서 학습 데이터를 과하게 학습하는 것이다. 학습된 데이터에만 정확하고, 실제 데이터가 들어오면 정확도가 더 떨어지게 되어버린다.

#사이킷런에서 knn라이브러리를 불러온다.
from sklearn.neighbors import KNeighborsClassifier
#부르기 쉽게 kn으로 줄여준다.
kn = KNeighborsClassifier()
#훈련데이터를 fitting 시켜준다.
kn.fit(x_train,y_train)
훈련데이터의 점수를 확인해보자.
kn.score(x_train,y_train)
과적합이 일어나지 않고 잘 학습되었는지 아까 나누어 준 테스트데이터로 점수를 확인해본다.
kn.score(x_test,y_test)
새로운 과일을 넣어서 모델을 확인해보자.

# 새로 넣어볼 과일의 지름과 무게
testfruit_D = 10.19
testfruit_W = 177.33
#새로 가져온 과일을 만든 knn알고리즘에 넣어서 확인해본다. 만약 오렌지면 [0], 자몽이면 [1] 값이 나온다.
testfruit = kn.predict([[testfruit_D,testfruit_W]])
#새로 넣은 과일과 기존 데이터를 시각적으로 보기위해 산점도 그래프를 그려본다.
plt.scatter(orange_diameter,orange_weight)
plt.scatter(grapefruit_diameter,grapefruit_weight)
plt.scatter(testfruit_D,testfruit_W,marker='s')
plt.xlabel('diameter')
plt.ylabel('weight')
plt.title("orange_grapefruit")
plt.show()
# 위에서 kn.predict 한 값을 출력한다. 만약 오렌지면 [0], 자몽이면 [1]로 출력된다.
print(testfruit)
# 좀더 직관적으로 보기 위해 0인지 1인지에 따라 문자열로 출력
if testfruit == 0:
print("orange")
else:
print("grapefruit")다음과 같이 자몽으로 판별했다.

이번엔 오렌지값을 넣어본다. 잘 나오는지 확인 하기 위해 지름이 위에 넣은 데이터와 같은(10.19)인 데이터를 골라 넣어보았다.

# 새로 넣어볼 과일의 지름과 무게
testfruit_D = 10.19
testfruit_W = 178.53
#새로 가져온 과일을 만든 knn알고리즘에 넣어서 확인해본다. 만약 오렌지면 [0], 자몽이면 [1] 값이 나온다.
testfruit = kn.predict([[testfruit_D,testfruit_W]])
#새로 넣은 과일과 기존 데이터를 시각적으로 보기위해 산점도 그래프를 그려본다.
plt.scatter(orange_diameter,orange_weight)
plt.scatter(grapefruit_diameter,grapefruit_weight)
plt.scatter(testfruit_D,testfruit_W,marker='s')
plt.xlabel('diameter')
plt.ylabel('weight')
plt.title("orange_grapefruit")
plt.show()
# 위에서 kn.predict 한 값을 출력한다. 만약 오렌지면 [0], 자몽이면 [1]로 출력된다.
print(testfruit)
# 좀더 직관적으로 보기 위해 0인지 1인지에 따라 문자열로 출력
if testfruit == 0:
print("orange")
else:
print("grapefruit")다음과 같이 오렌지로 판별했다.

비슷한 값을 넣었지만 잘 구별하는 것으로 보여진다. 하지만 데이터셋을 2개로 나누고, 데이터셋에서 없는 완전 새로운 데이터를 넣어준 것은 아니기 때문에 이렇게 정확하게 나온 걸 수도 있다. 만약 더 정확히 확인하기 위해서는 마트에서 오렌지나 자몽을 사서 지름과 무게를 측정하여 테스트 해 보면 될 것 같다. 또 이번 예제에서는 무게와 지름에 대해 스케일링을 해주지 않고도 잘 동작했지만, 만약 고려해야하는 특징의 스케일링이 필요하다면 그부분을 추가해야 할 것이다.
전체 파이썬 코드 ipynb 파일은다음 github링크에서 볼 수 있다.
github.com/dol42/knn_fruit/blob/main/fruit.ipynb
dol42/knn_fruit
Contribute to dol42/knn_fruit development by creating an account on GitHub.
github.com
'개발관련 > 인공지능,머신러닝,딥러닝' 카테고리의 다른 글
| Google TeachableMachine + Python 간단한 프로그램 제작하기 (5) | 2021.02.22 |
|---|---|
| 딥러닝과 머신러닝의 차이 (2) | 2021.01.03 |
| 인공지능, 머신러닝, 딥러닝이란? (2) | 2020.12.31 |